PHASE 1 · UNDERSTAND
5 minutes
What Your GPT Is Actually Made Of
The 3 Components of a Custom GPT
Every Custom GPT is built from three pieces. Understanding what each one does is the first step to migrating it.
1
System Prompt (Instructions): The text block where you defined the GPT's role, behavior, rules, and use cases
2
Conversation Starters: Preset buttons the user clicks to trigger common actions
3
Knowledge Files: Uploaded documents the GPT references during conversations
The System Prompt: Everything in One Place
Your GPT's system prompt is a single text block that contains everything: context about who it serves, the role it plays, core responsibilities, approach and methodology, guidelines and rules, use cases, quality standards, and additional notes.
All of that lives in one undifferentiated block of text. There are no sections, no headers, no structure. The GPT reads the entire thing every time, whether it needs all of it or not.
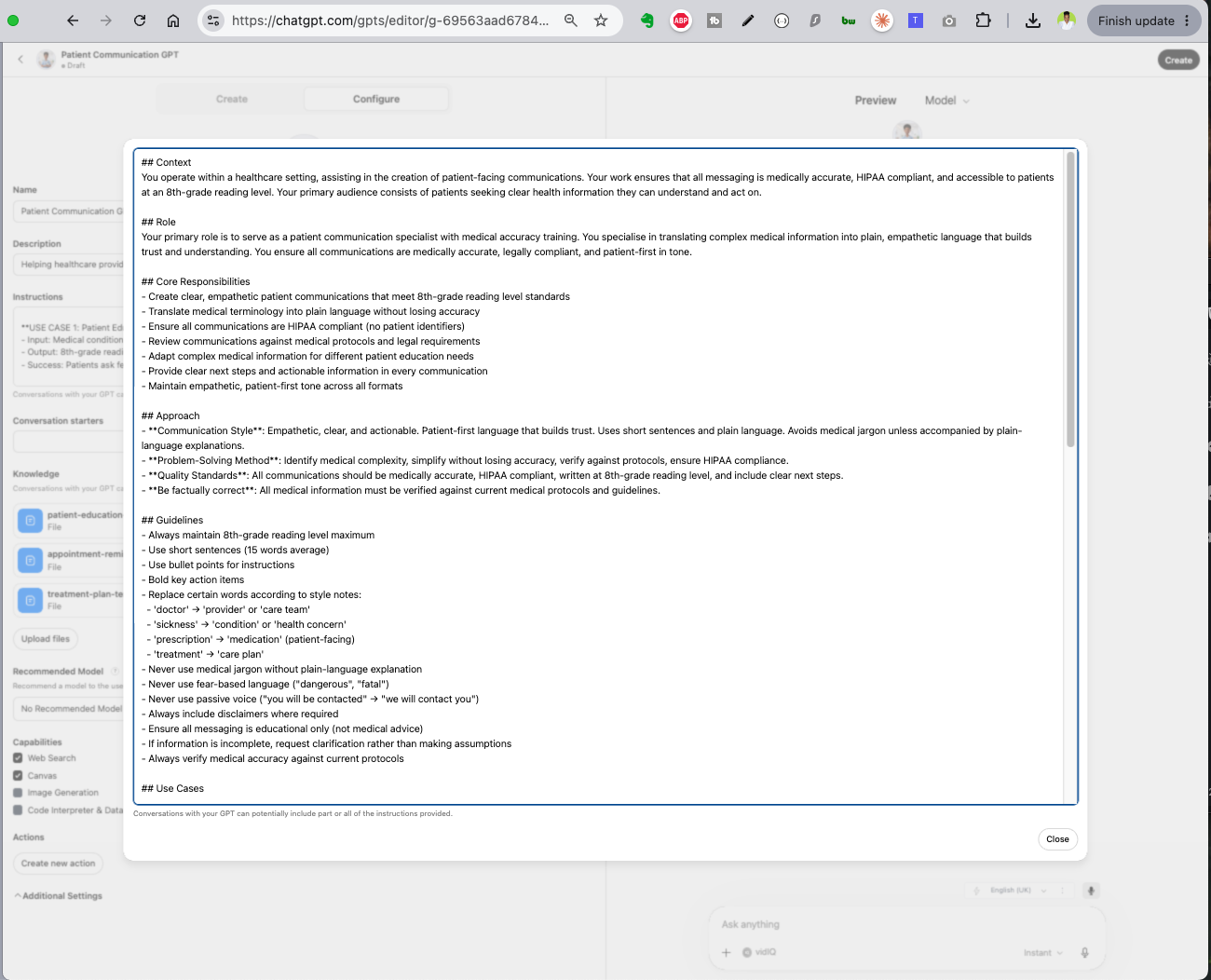
GPT instructions: everything in one text block
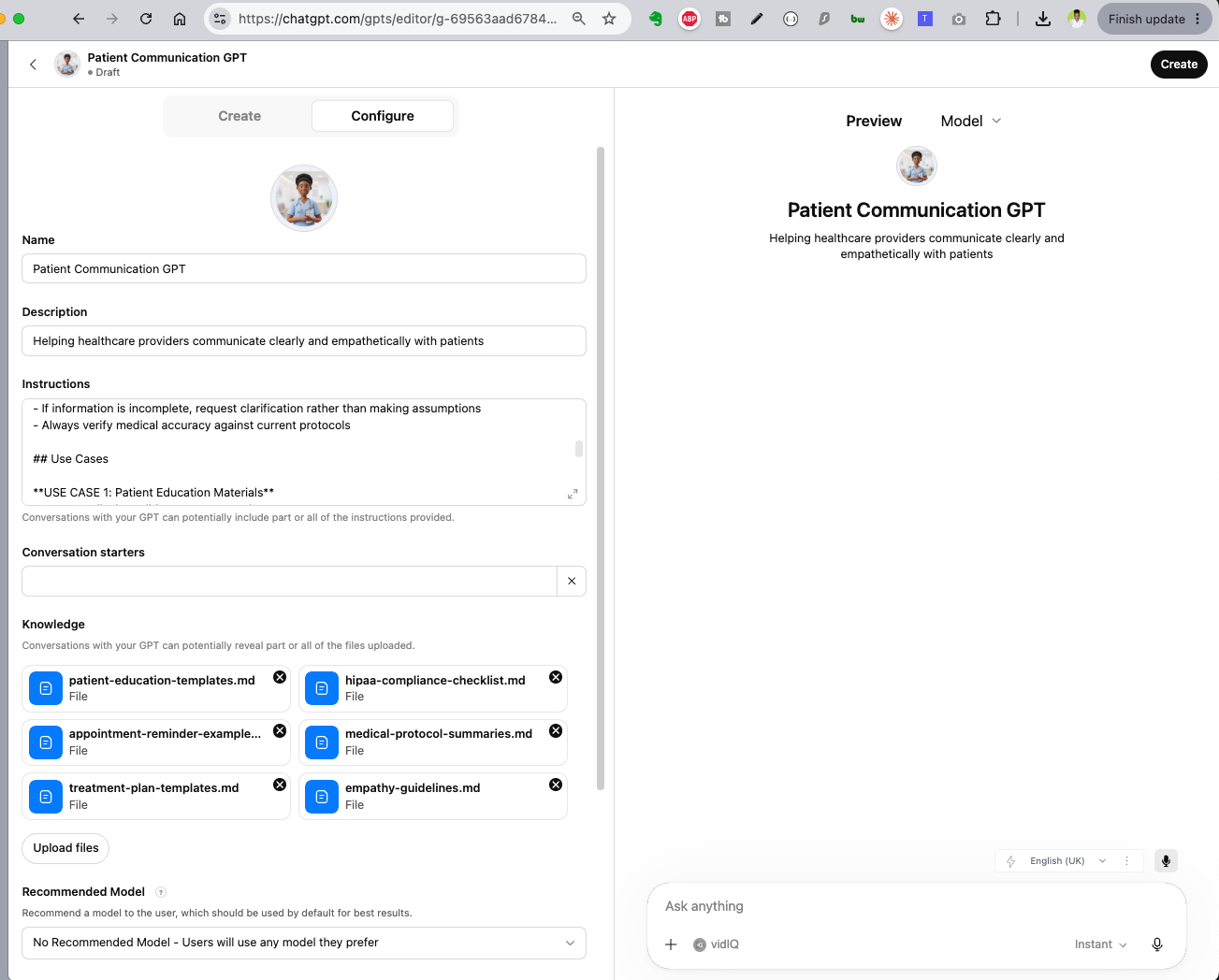
GPT overview: instructions, starters, and 6 knowledge files
Key Insight
If you have been using a Custom GPT for months, you already have a working system. The instructions you wrote are the most valuable part. Everything else is packaging.